


Redes Neuronales Convolucionales para Procesamiento del Lenguaje Natural


Las redes neuronales artificiales son un modelo inspirado en el funcionamiento del cerebro humano. El objetivo de este modelo es aprender modificándose automáticamente a sí mismo para realizar tareas que no pueden ser llevadas a cabo mediante la programación clásica.
Las Redes de Convolución son un tipo de Redes Neuronales que se utilizaron por primera vez en procesamiento de imágenes. El primer problema que se resolvió fue reconocer dígitos escritos a mano a los cuales se les tomaba una foto y había que reconocer qué número era mediante esa foto.
También se utilizaron para establecer diferencias entre una imagen y otra, como por ejemplo que contengan dos animales diferentes, o cualquier cosa que se pueda plasmar en una matriz con sus filas y columnas, es decir, cualquier imagen.
Esto evolucionó y se convirtió en el campo actualmente denominado “Visión por Computadora”. Con el paso del tiempo los investigadores comprendieron que las Redes Neuronales por Convolución también podían ser una herramienta muy potente para procesar el lenguaje, el texto.
Las Redes de Convolución se suelen utilizar para tareas de clasificación, como por ejemplo, detectar spam o fraude, fishing o tareas de análisis de sentimientos.
El siguiente artículo aborda el desarrollo de la teoría de RNC que se debe tener en cuenta para luego poder construir una aplicación de análisis de sentimientos en la red social Twitter que será publicado como la segunda parte de este artículo.
El orden de desarrollo será el siguiente:
- RNC básicas para imágenes
- Pasar de imagen a texto
- RNC aplicadas a texto
RNC básicas para imágenes
¿Qué es una Red Neuronal Convolucional y cómo funciona?
Es un red neuronal que toma de entrada una imagen y su salida es una etiqueta, es decir, la salida es la categoría a la cual pertenece la imagen. Por ejemplo, que la entrada sea la imagen de un sólo número y las clases o categorías para clasificar el número sean 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
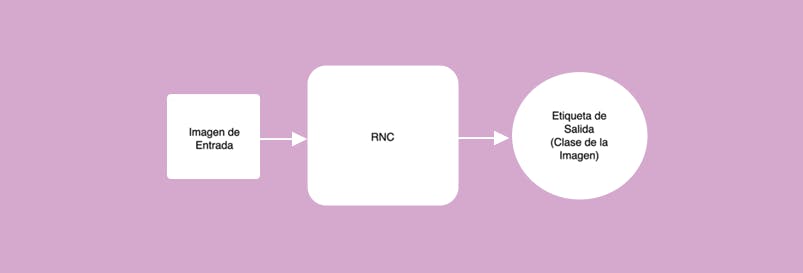
Pasos para crear una red neuronal convolucional:
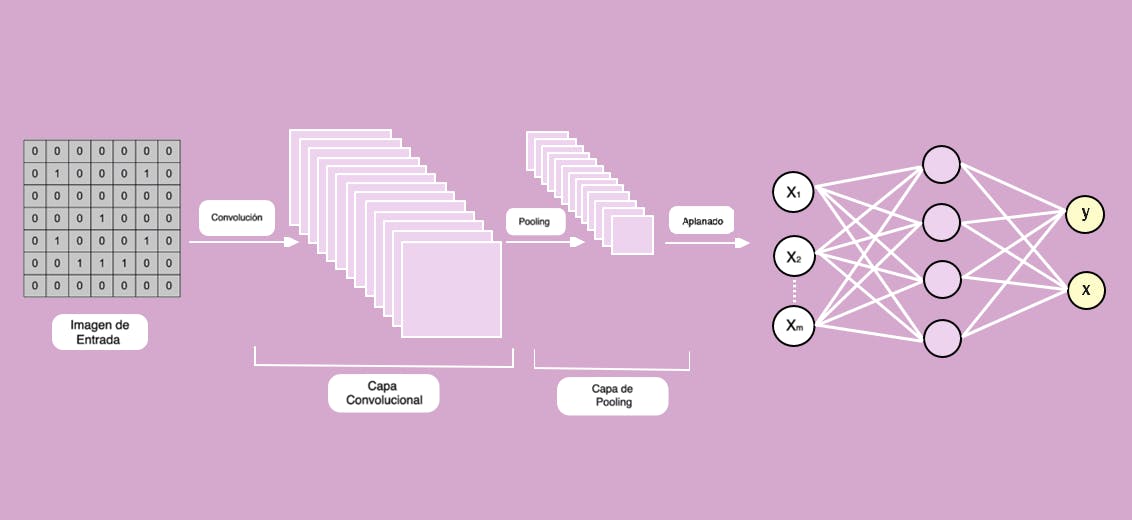
Paso 1: La convolución. En este primer paso creamos detectores de rasgos que van a recorrer toda la imagen. y van a ser un mapa de características que va a indicar si cierto rasgo, aparece o no en la imagen.

Ahora, teniendo en cuenta la posición del cuadrado que se marca, se realiza el producto de convolución de la imagen de entrada con el detector de características que se observa.
El producto se realiza elemento a elemento y tales números multiplicados luego se suman obteniendo un único valor que representa una casilla en el mapa de características.
El cuadrado marcado se va desplazando por toda la imagen de entrada. Observe que donde hay un 1 en el detector de características, también hay un 1 en la imagen de entrada, por lo tanto cuando hacemos el producto y sumamos, obtenemos el segundo elemento en el mapa de características, que es igual a 1.
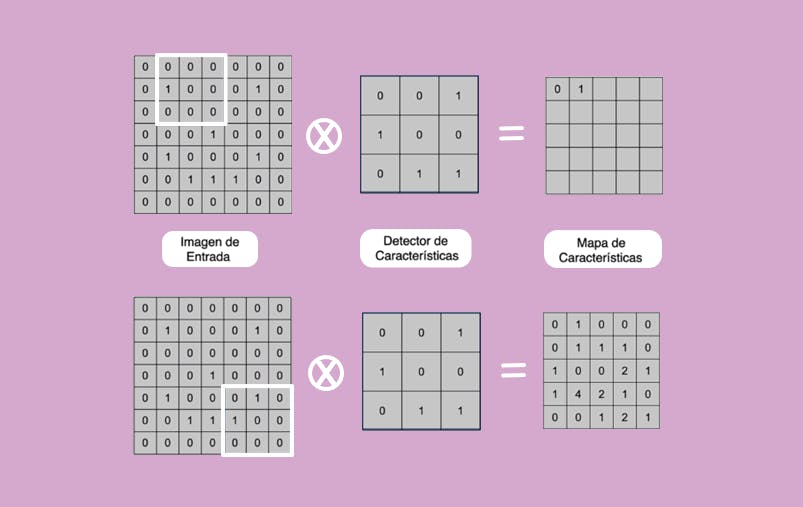
En este ejemplo hay sólo un detector de características y la idea es que la red convolucional utilice más cantidad de detectores, y para cada uno de ellos un mapa de características determinado, con el fin de que se filtre la imagen original y poder saber qué tan probable es que el mapa aparezca en la imagen de entrada.
Para construir el detector de características, al principio de inicializa con números aleatorios y son los que la red neuronal irá aprendiendo como parte del proceso de entrenamiento.
Después de cada predicción se comparan los resultados que devuelve la red neuronal con la etiqueta real que tuvieran las imágenes, y por lo tanto el modelo podrá ver cuánto se ha equivocado, también ver cuáles detectores de características le funcionan mejor o peor, y en base a esto cambiar los números de los detectores de características.
Cada una de las tareas de clasificación necesitará unos detectores de características exclusivamente determinados para cada caso.
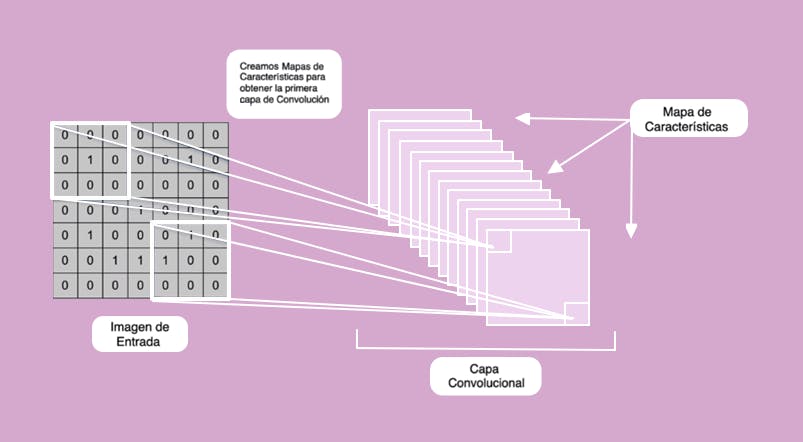
Después de aplicar esta operación a la imagen original, terminará siendo una gran lista de mapas de características, cada uno se identifica con un detector de características y cada uno habrá detectado diferentes formas a través de la convolución, gracias a los filtros que la propia red neuronal habrá ido aprendiendo con el entrenamiento.
De este modo, cada uno de los mapas de características contendrá información de la forma que se detecta o no, sobre las cuales la red neuronal es capaz de utilizar. Esto nos conduce al segundo paso.
Paso 2: El segundo paso es el Max Pooling (o máximo local), que se trata sobre aplicar una función Máximo a cada uno de los mapas de características, de modo que los hacemos cada vez más pequeños evitando tener exceso de información. El Max Pooling reduce el tamaño y el costo, convirtiéndolo en más genérico.
Se aplica la operación de máximo a cada uno de los mapas de características con el objetivo de reducir el tamaño y el costo de computación del modelo global.
El máximo que se calcula puede ser global o no, es decir, realizarlo en todos los mapas de características o de manera local con el objetivo de reducir la cantidad de mapas de características.
Con el mapa de características trabajado en el paso 1, la idea es tomar una ventana de 2x2 y la desplazamos de manera que nos permite reducir, de cada 4 números quedarnos con el máximo de esa posición.
Es una operación de máximo que se lleva a cabo para cada una de las posiciones a medida que se desplaza la ventana. De esta manera se reducirá el tamaño y el costo, vamos a conseguir que la información sea más pequeña.
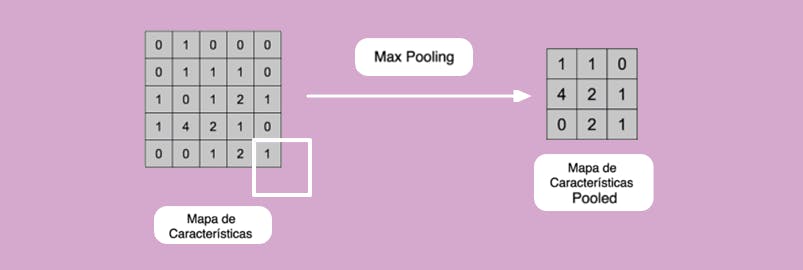
Obtenemos un número que resume cada una de las ventanas que se desplazan, lo importante es saber si este número aparece en la imagen original y su posición.
Tenemos un mapa de características simplificado, nos deshacemos de información innecesaria. Esto debe realizarse para todo y cada uno de los mapas de la primera fase y nos quedamos con sus valores pooleados.
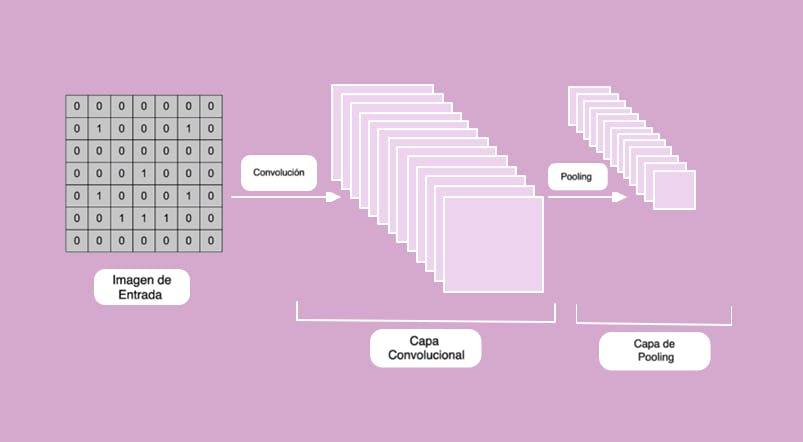
Paso 3: Aplanado. En este tercer paso tomamos los mapas de características, que son matrices bidimensionales y las “aplanamos” para crear un vector extenso y será la entrada al cuarto paso.
La idea es ordenar toda la información que ha salido para que sea un vector que podamos suministrar a nuestra red neuronal. Una Red Neuronal totalmente conectada necesita un vector en la capa de entrada. Por lo tanto, tomamos cada uno de los mapas de características pooleados y los transformamos de matriz a vector vertical.
Este vector vertical pasará a ser el vector de entrada de la red neuronal. Se toma la primera fila y se convierte en los primeros elementos del vector aplanado, seguido de la segunda fila y la tercera fila, pasando de matriz a vector.
Es importante destacar que el aplanado conserva todavía las relaciones de posiciones de los elementos, por lo tanto esa información local todavía mantiene la posición relativa entre los objetos.
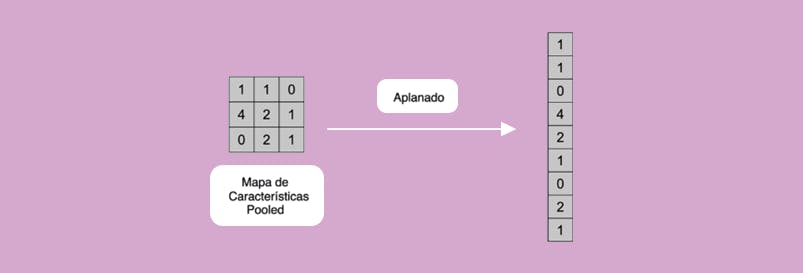
Tendremos, entonces, un vector extenso que serán todos los mapas de características aplanados, uno encima de otro de modo que esas serían las entradas de la red neuronal convolucional. Sería entonces, un macro vector para la capa de entrada de la red neuronal.
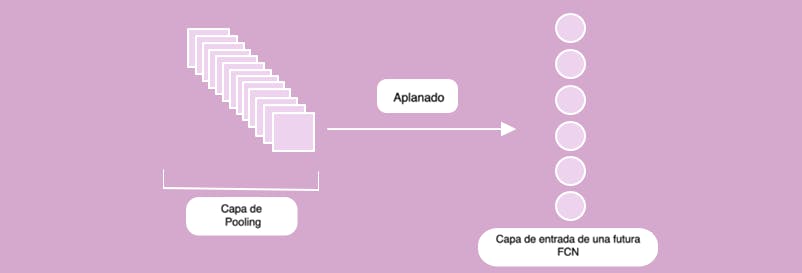
Ilustración de los pasos realizados hasta ahora:
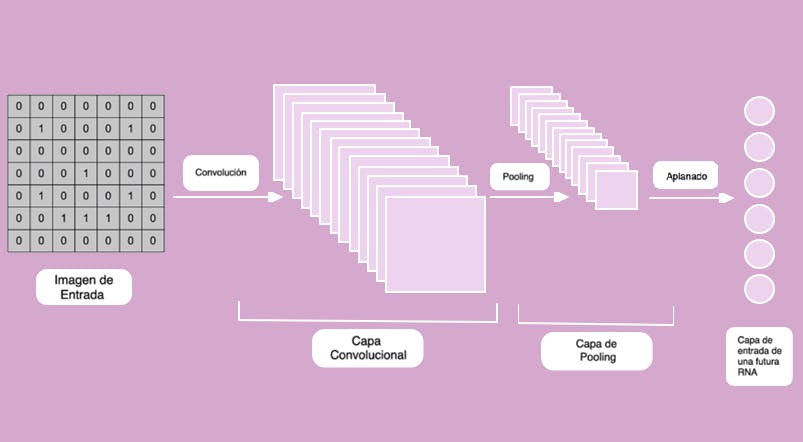
Paso 4: Conexión completa. Obtenemos una red neuronal totalmente conectada con capas ocultas que aprenderá de los rasgos extraídos de los mapas de características pooleados y aplanados. Esto será la capa de entrada y cuya salida será la etiqueta, es decir, a qué etiqueta corresponde la imagen que le proporcionamos a la red neuronal.
En este capo tenemos una sola capa oculta y la idea es poder añadir la cantidad de capas ocultas que se quisieran, las cuales pueden tener la cantidad de neuronas que se quieran.
Se debe tener en cuenta que al agregar más neuronas la arquitectura sea más compleja y se necesitarán más cálculos.
En la entrada tenemos el vector que obtuvimos en el paso 3, y la salida son las posibles categorías, las etiquetas de clasificación, en este caso hay dos categorías posibles.
Si hubiese más salidas y el número que saldría representaría la verosimilitud, la probabilidad de que una imagen corresponda a dicha categoría. Cuando mayor es el número de la capa de salida, mayor es la probabilidad de que la imagen de entrada a la cual se aplica el proceso, pertenezca a dicha categoría.
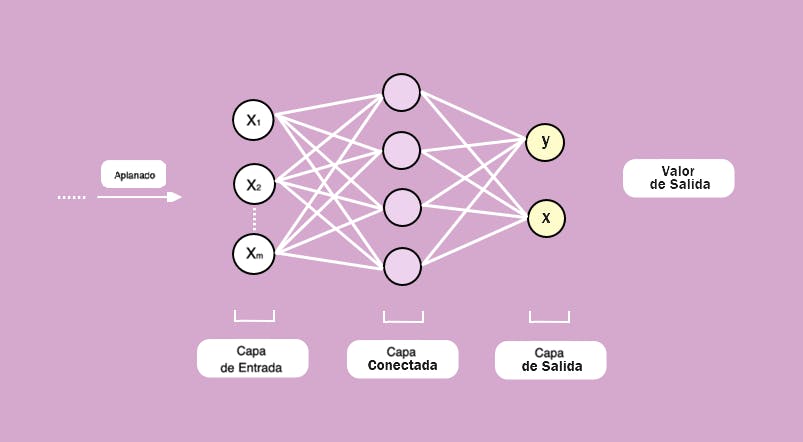
Una red neuronal sólo sabe multiplicar y sumar.
Cada una de las flechas tiene unos pesos, los cuales se multiplican para cada uno de los valores de la capa de entrada y una vez que se hayan multiplicado peso x valor, se suman para sacar un número dentro de cada una de las neuronas de la capa oculta (color lila).
Normalmente esta relación sería lineal, y para romper esa linealidad (ya que la mayoría de la información no tendría por qué ser lineal) a esa suma ponderada se le aplica una función de activación RELU (Rectificadora Lineal Unitaria).
Básicamente RELU lo que hace es, si un producto y suma ha dado un número negativo le corresponderá un 0, y si sale positivo le corresponde el valor que sale.
Entonces nos deshacemos de información que no aporta nada y nos quedamos con la que importa. Si hubiese dos capas densas, tres, cuatro, etc., esta operación se repite para cada una de las capas dentro. Se basa en la arquitectura de redes neuronales artificiales comúnmente usadas.
La categoría que tenga mayor probabilidad en las salidas de la red artificial será la categoría que debemos aplicarle a la imagen, y a través del entrenamiento debemos ir corrigiendo los errores, la propia red irá ajustando los mapas de características.